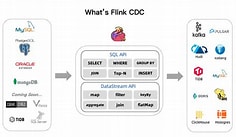
从零开始学Flink:Flink CDC 入门
先搞懂:CDC 到底是什么?
CDC,全称 Change Data Capture(变更数据捕获),说白了就是:数据库里每发生一次增删改,我都能立刻感知到,并把它变成一条实时消息发出去。
打个比方:
传统方式像是在仓库门口装了个摄像头,每隔 30 分钟回看一次录像,看看有没有货进出。
CDC 则是直接在每件货物上贴了个传感器——货一动,你手机上立刻收到通知。
Flink CDC 就是这个传感器系统里最成熟的实现方案之一。它直接读取 MySQL 的 Binlog(二进制日志)——MySQL 用来做主从复制的那个日志,相当于数据库的"行车记录仪",每一笔增删改都被原原本本地记录在里面。
Flink CDC 不会对源库加锁,不影响线上业务。 这是它最核心的优势。
工作原理:一次看懂"增量快照"
Flink CDC 的工作过程分两步,这个"增量快照"机制是理解它的关键:
阶段一:全量快照(Snapshot)
启动时,Flink CDC 会把整张表切成多个小块(叫 Chunk),多线程并行读取,速度极快。读的时候不加锁,靠的是一个巧妙算法:
- 记录当前 Binlog 位置为 LOW
- 读取这个 Chunk 的数据
- 记录当前位置为 HIGH
- 把 LOW 到 HIGH 之间的 Binlog 变更补进来
- 最终结果以 INSERT 形式发往下游
阶段二:增量订阅(Streaming)
全量读完后,无缝切换到单线程持续消费 Binlog,所有新的 INSERT、UPDATE、DELETE 毫秒级同步。
全量快照(并行多Chunk) → 切换 → 增量订阅(实时Binlog消费)
↓ ↓
INSERT 事件 INSERT/UPDATE/DELETE 事件一句话总结:先用快照把存量搬过来,再盯住 Binlog 把增量补上。 既快,又准,还不锁表。
.png)
动手实战:Flink SQL 3 步搭建 MySQL → Kafka 管道
说了这么多原理,直接上代码。下面用 纯 Flink SQL 完成从零搭建 MySQL 到 Kafka 的 CDC 管道。
环境准备
正式开始前,先把依赖和环境搞定。
下载所需 JAR 包
Flink 发行版默认不带 CDC 和 Kafka 连接器,需要手动下载以下 4 个 JAR 放到 <FLINK_HOME>/lib/:
| JAR 包 | 下载地址 | 作用 |
|---|---|---|
flink-sql-connector-mysql-cdc | Maven 仓库 | MySQL CDC 源连接器 |
flink-connector-kafka | Maven 仓库 | Kafka 连接器(写 Kafka 必需) |
kafka-clients | Maven 仓库 | Kafka 客户端(序列化器依赖,缺了会报 ByteArraySerializer) |
mysql-connector-java | Maven 仓库 | MySQL JDBC 驱动 |
最终 lib/ 目录:
<FLINK_HOME>/lib/
├── flink-sql-connector-mysql-cdc-3.6.0-2.2.jar # CDC 连接器(读 MySQL)
├── flink-connector-kafka-4.0.1-2.0.jar # Kafka 连接器(写 Kafka)
├── kafka-clients-4.0.1.jar # Kafka 客户端依赖
├── mysql-connector-java-8.0.27.jar # MySQL JDBC 驱动
└── ...(Flink 自带的其他 JAR)📌 下载后记得 重启 Flink 集群,新加的 JAR 才会被加载。
配置 MySQL 用户权限
CDC 需要读取 Binlog,所以 MySQL 用户得有相应权限:
-- 创建专用用户
CREATE USER 'flink_cdc'@'%' IDENTIFIED BY 'flink_cdc_123';
-- 授予必要权限
GRANT SELECT, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'flink_cdc'@'%';
-- 刷新权限
FLUSH PRIVILEGES;权限说明:
| 权限 | 用途 |
|---|---|
SELECT | 读取表数据(全量快照需要) |
SHOW DATABASES | 获取数据库列表 |
REPLICATION SLAVE | 读取 Binlog(增量订阅核心) |
REPLICATION CLIENT | 查看 Binlog 状态位点 |
开启 MySQL Binlog
编辑 MySQL 配置文件 my.cnf(或 my.ini):
[mysqld]
server-id = 1
log-bin = mysql-bin
binlog_format = ROW # 必须是 ROW 模式
binlog_row_image = FULL # 记录完整行数据改完后重启 MySQL,验证是否生效:
SHOW VARIABLES LIKE 'log_bin';
-- 结果应为 ON
SHOW VARIABLES LIKE 'binlog_format';
-- 结果应为 ROW创建测试库和表
-- 创建数据库
CREATE DATABASE shop_db;
USE shop_db;
-- 创建订单表
CREATE TABLE orders (
order_id INT PRIMARY KEY AUTO_INCREMENT,
customer_name VARCHAR(100) NOT NULL,
price DECIMAL(10, 2) NOT NULL,
order_status VARCHAR(20) DEFAULT 'pending',
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 插几条初始数据,方便验证全量快照
INSERT INTO orders (customer_name, price, order_status) VALUES
('张三', 99.00, 'paid'),
('李四', 150.50, 'pending'),
('王五', 200.00, 'paid');环境准备完毕!接下来正式进入 Flink SQL 环节。
第 1 步:开启 Flink Checkpoint
-- 实时任务必须开 Checkpoint,保证故障恢复
SET 'execution.checkpointing.interval' = '3s';第 2 步:定义 MySQL CDC 源表
CREATE TABLE orders_source (
order_id INT,
customer_name STRING,
price DECIMAL(10, 2),
order_status STRING,
create_time TIMESTAMP(0),
PRIMARY KEY (order_id) NOT ENFORCED -- 声明主键,Flink 用于去重和更新
) WITH (
'connector' = 'mysql-cdc', -- 使用 mysql-cdc 连接器
'hostname' = 'localhost',
'port' = '3306',
'username' = 'flink_cdc',
'password' = 'flink_cdc_123',
'database-name' = 'shop_db',
'table-name' = 'orders',
'server-id' = '1-5404' -- 并行快照所需的唯一 server-id 范围
);重点参数解释:
| 参数 | 作用 |
|---|---|
connector = 'mysql-cdc' | 告诉 Flink 这是一个 CDC 源 |
server-id | 模拟多个 MySQL Slave,并行读取用 |
PRIMARY KEY NOT ENFORCED | Flink 不会强制校验,但用于优化 upsert 操作 |
第 3 步:定义 Kafka 目标表并启动同步
-- 定义 Kafka 目标表
CREATE TABLE orders_sink (
order_id INT,
customer_name STRING,
price DECIMAL(10, 2),
order_status STRING,
create_time TIMESTAMP(0),
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka', -- upsert 模式,支持更新和删除
'topic' = 'ods_orders',
'properties.bootstrap.servers' = 'localhost:9092',
'key.format' = 'json',
'value.format' = 'json'
);
-- 一行 SQL 启动实时同步管道!
INSERT INTO orders_sink SELECT * FROM orders_source;就这 3 步,管道跑起来了!
现在你在 MySQL 里做任何操作:
UPDATE orders SET order_status = 'shipped' WHERE order_id = 1;
DELETE FROM orders WHERE order_id = 1;Kafka 消费者会实时收到对应的 JSON 消息,延迟在 毫秒级。

写在最后
回顾这条实时管道,本质上只做了三件事:
- 连接 MySQL Binlog → 捕获数据变更
- Flink 作为流处理引擎 → 低延迟传输和转换
- 写入 Kafka → 下游消费解耦
但就是这三步,把数据延迟从 分钟级拉到了毫秒级,把运维从"手动导数据"解放成了"配置即运行"。
实时数据不再是奢侈品,而是基础设施。
如果你还在用定时任务倒数据,今晚就试试 Flink CDC 吧——它可能比你想象中简单得多。
关注【代码匠心】,回复关键字 flink,获取 Flink 学习资料!