先搞懂:CDC 到底是什么?
CDC,全称 Change Data Capture(变更数据捕获),说白了就是:数据库里每发生一次增删改,我都能立刻感知到,并把它变成一条实时消息发出去。
打个比方:
传统方式像是在仓库门口装了个摄像头,每隔 30 分钟回看一次录像,看看有没有货进出。
CDC 则是直接在每件货物上贴了个传感器——货一动,你手机上立刻收到通知。
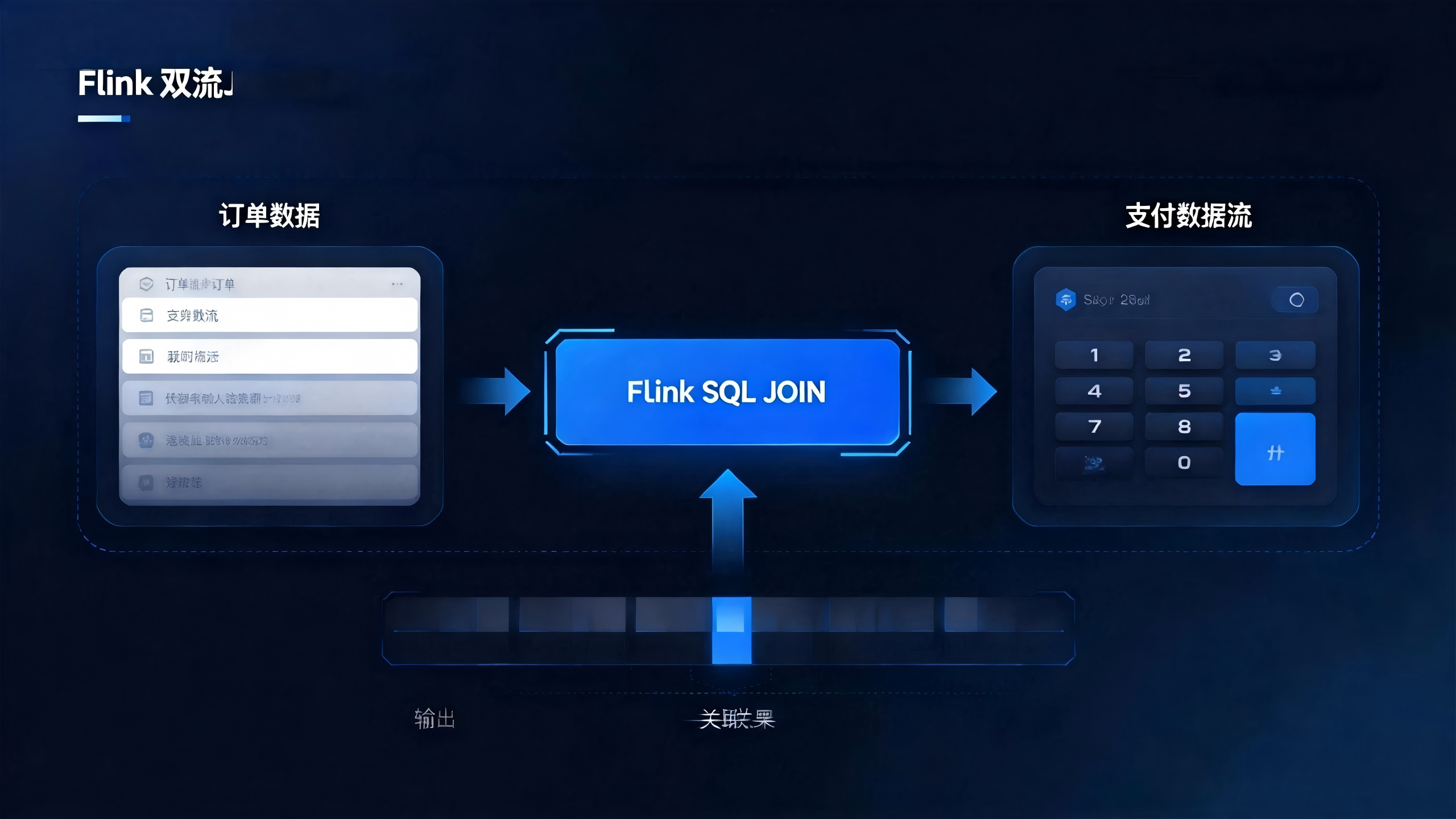
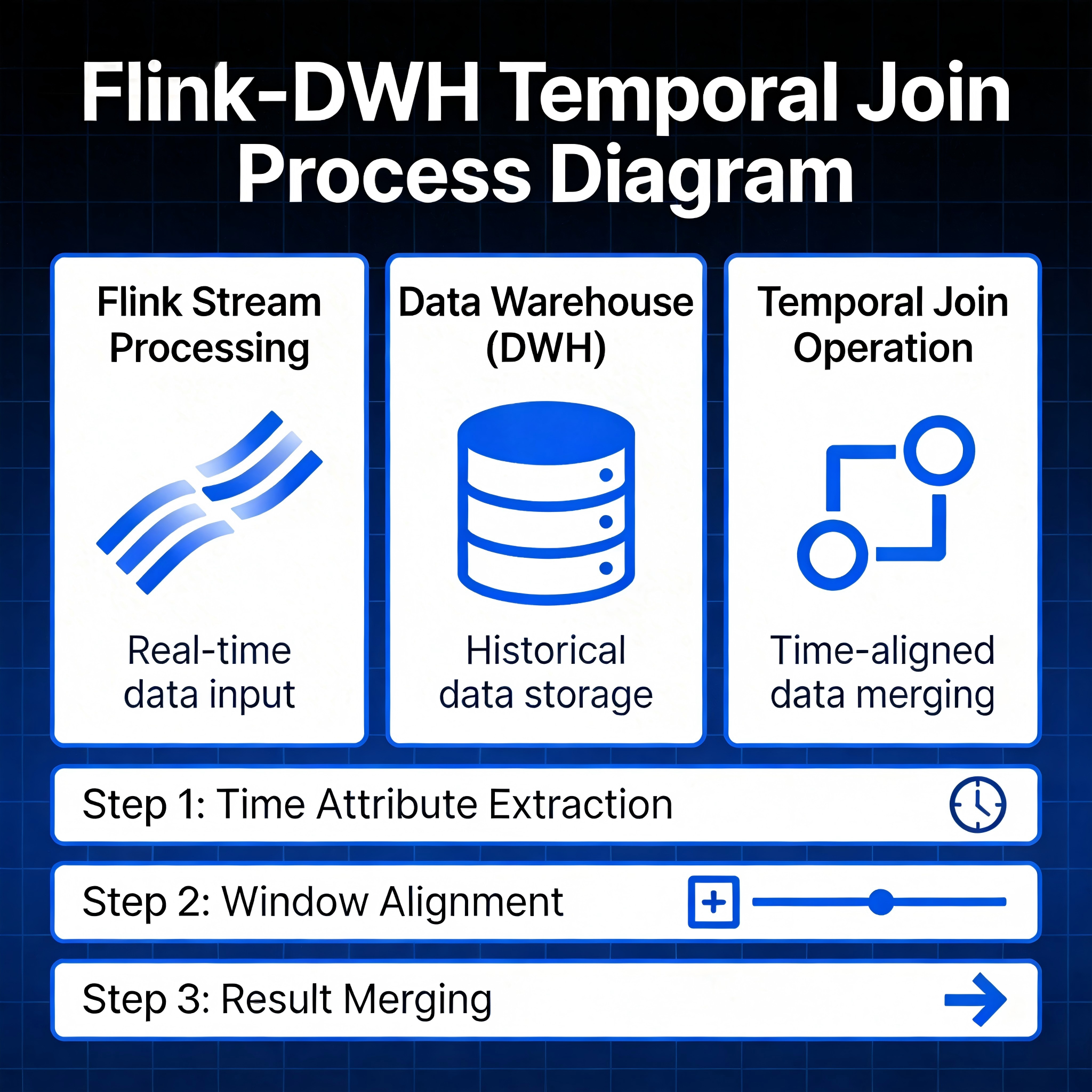
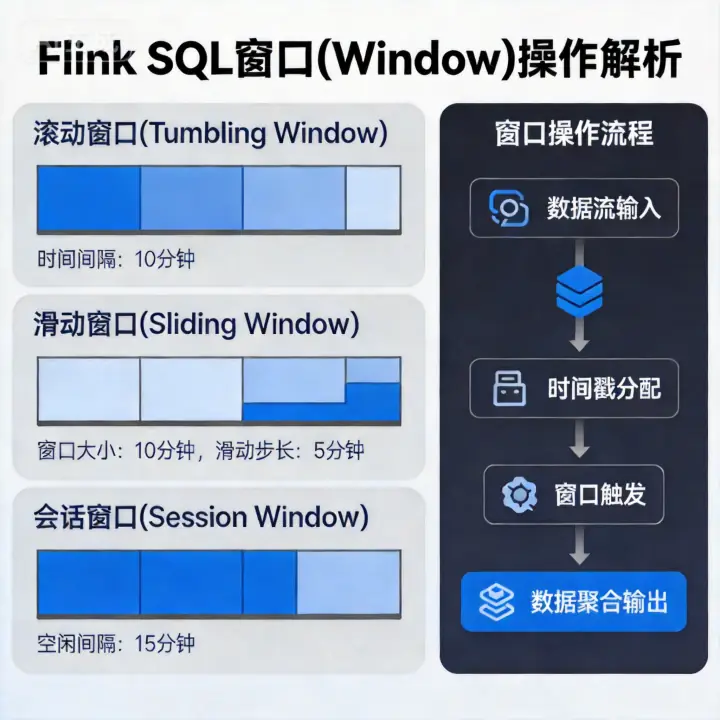
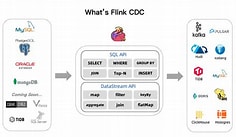
Flink CDC 就是这个传感器系统里最成熟的实现方案之一。它直接读取 MySQL 的 Binlog(二进制日志)——MySQL 用来做主从复制的那个日志,相当于数据库的"行车记录仪",每一笔增删改都被原原本本地记录在里面。
2026/5/31大约 6 分钟