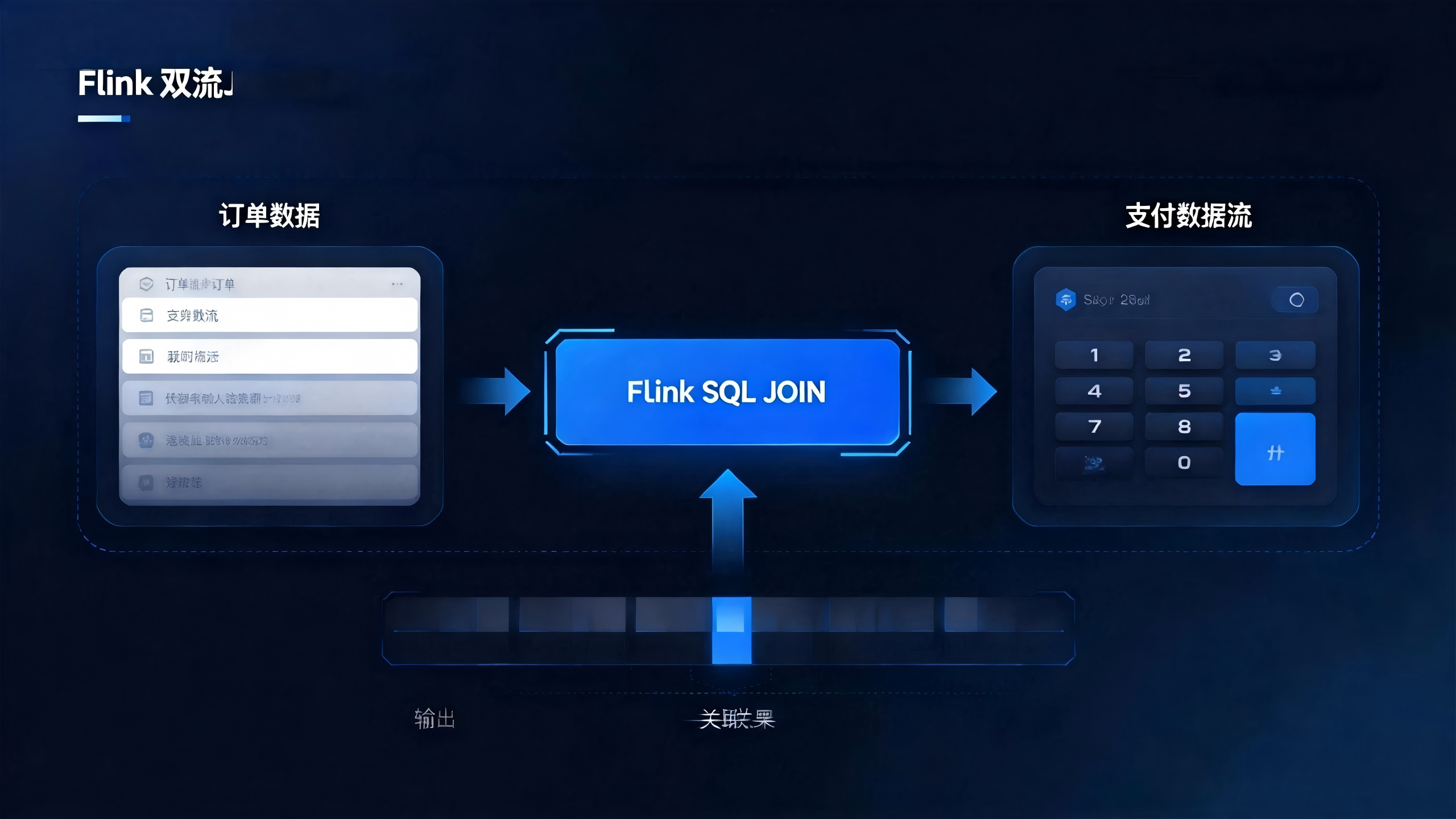
在前一篇 《Flink SQL 窗口(Window)操作详解》 中,我们已经打好了时间与窗口的基础。
但在真实业务里,单条流上的聚合往往只是第一步,更常见的需求是把多条业务流关联起来一起看,例如:
- 订单流 + 支付流:衡量下单到付款的转化效果
- 浏览流 + 下单流:分析从曝光、点击到下单的完整漏斗
- 用户行为流 + 用户画像维表:驱动推荐、风控等在线决策
2026/2/16大约 7 分钟
在前一篇 《Flink SQL 窗口(Window)操作详解》 中,我们已经打好了时间与窗口的基础。
但在真实业务里,单条流上的聚合往往只是第一步,更常见的需求是把多条业务流关联起来一起看,例如:
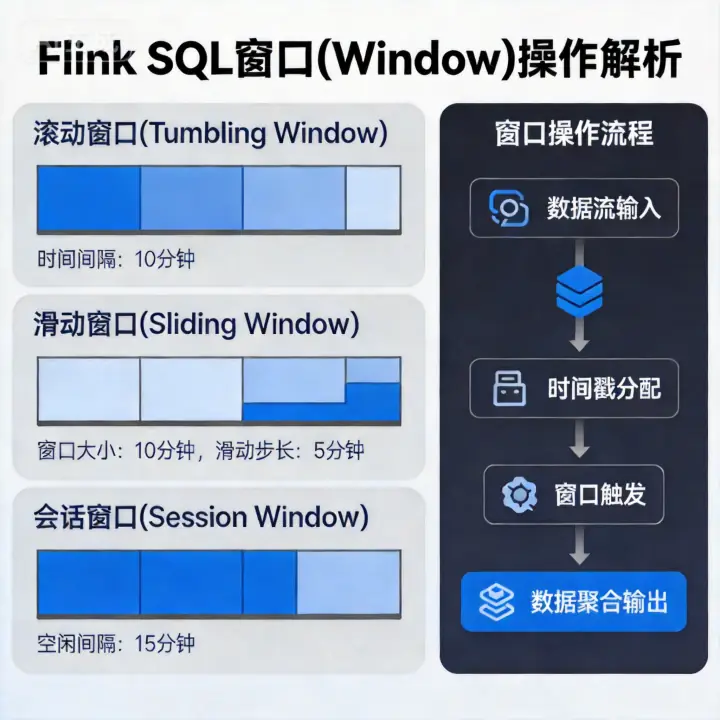
在上一篇 Flink SQL 极简入门 中,我们体验了 Flink SQL 的基础用法。但在流处理中,最核心、最迷人(也最让人头秃)的概念莫过于**“时间”和“窗口(Window)”**。
你可能经常听到这样的业务需求:
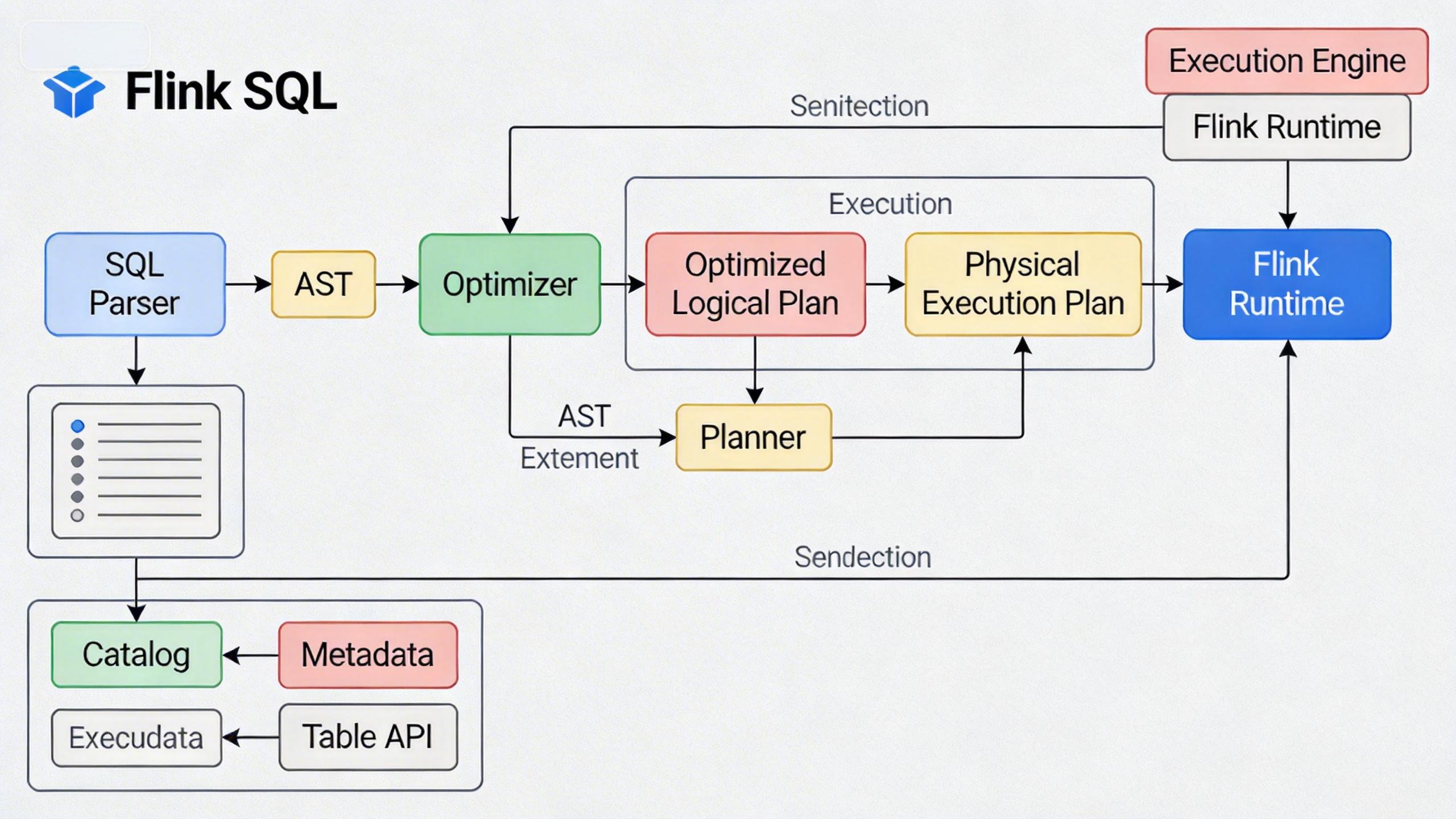
Flink SQL 是 Apache Flink 的核心模块之一,它让开发者可以使用标准的 SQL 语法来编写流处理和批处理作业。对于不想深究 Java/Scala 复杂 API 的“小白”来说,Flink SQL 是进入实时计算领域的最佳敲门砖。
本文将基于 Flink 1.20.1 版本,手把手教你在 WSL2 (Ubuntu) 环境下搭建环境,并运行你的第一个 Flink SQL 任务。

流式计算任务通常需要 7x24 小时长期运行,面对网络抖动、机器故障或代码 Bug,如何保证任务不挂?或者挂了之后能自动恢复且数据不丢、不重?这正是 Flink 引以为傲的资本:强大的状态管理与基于 Checkpoint 的容错机制。
本文将带你深入理解 Flink 是如何“记忆”数据的,以及它是如何在故障发生时“时光倒流”恢复现场的。
在流计算中,数据是一条条流过的。如果处理一条数据时,需要依赖之前的数据(例如:计算过去一小时的总和、去重、模式匹配),那么这些“之前的数据”或“中间计算结果”就是状态。
在实时计算领域,很多业务逻辑天然适合“事件驱动”模式:当事件到达时触发处理、在某个时间点触发补偿或汇总、根据状态变化发出告警等。Apache Flink 为此提供了强大的 ProcessFunction 家族(KeyedProcessFunction、CoProcessFunction、BroadcastProcessFunction 等),它们在算子层面同时具备“事件处理 + 定时器 + 状态”的能力,是构建复杂流式应用的核心基石。
本文基于 Flink 1.20 的语义,带你从零理解事件驱动的编程模型,并一步步实现一个“伪窗口 PseudoWindow”示例,体会 ProcessFunction 如何代替窗口完成时间分桶、累加和触发输出。
在当今数据爆炸的时代,企业面临着前所未有的数据处理挑战——如何同时满足海量历史数据的批处理分析需求和实时数据的低延迟查询需求?2014年,Storm的作者Nathan Marz提出了一种革命性的架构模式——Lambda架构,为解决这一矛盾提供了优雅的解决方案。
Lambda架构通过巧妙地将数据处理分解为批处理层(Batch Layer)、加速层(Speed Layer)和服务层(Serving Layer),实现了兼具高容错性、低延迟和可扩展性的大数据处理系统。本文将深入剖析Lambda架构的设计理念、核心组件、实现方式及应用场景,为大数据架构师提供一份全面的技术指南。
在大数据处理领域,批处理和流处理曾经被视为两种截然不同的范式。然而,随着Apache Flink的出现,这种界限正在逐渐模糊。Flink的一个核心特性是其批流一体的架构设计,允许用户使用统一的API和执行引擎处理有界数据(批处理)和无界数据(流处理)。本文将深入探讨Flink的执行模式(Execution Mode),特别是在Flink 1.20.1版本中对批处理和流处理模式的支持和优化。
Flink的执行模式决定了作业如何被调度和执行。在Flink 1.12及以后的版本中,引入了统一的流批处理执行模式,主要包括以下三种模式:
在大数据处理领域,实时流处理正变得越来越重要。Apache Flink作为领先的流处理框架,提供了强大而灵活的API来处理无界数据流。本文将通过经典的SocketWordCount示例,深入探讨Flink实时流处理的核心概念和实现方法,帮助你快速掌握Flink流处理的实战技能。
流处理是一种持续处理无界数据的计算范式。与批处理不同,流处理系统需要在数据到达时立即处理,而不是等待完整数据集收集完毕。在Flink中,所有数据都被视为流,无论是有界的历史数据还是无界的实时数据流。
在实时数据处理的完整链路中,数据输出(Sink)是最后一个关键环节,它负责将处理后的结果传递到外部系统供后续使用。Flink提供了丰富的数据输出连接器,支持将数据写入Kafka、Elasticsearch、文件系统、数据库等各种目标系统。本文将深入探讨Flink数据输出的核心概念、配置方法和最佳实践,并基于Flink 1.20.1构建一个完整的数据输出案例。
Sink(接收器)是Flink数据处理流水线的末端,负责将计算结果输出到外部存储系统或下游处理系统。在Flink的编程模型中,Sink是DataStream API中的一个转换操作,它接收DataStream并将数据写入指定的外部系统。
在实时数据处理流程中,数据转换(Transformation)是连接数据源与输出结果的桥梁,也是体现计算逻辑的核心环节。Flink提供了丰富的数据转换操作,让开发者能够灵活地对数据流进行各种处理和分析。本文将以Flink DataStream API为核心,带你探索Flink数据转换的精妙世界,并结合之前文章中的Kafka Source实现一个完整的数据处理流程。
数据转换是指将原始输入数据通过一系列操作转换为所需输出结果的过程。在Flink中,这些操作主要分为以下几类: