
在上一篇 《从零开始学Flink:实时数仓与维表时态Join实战》 中,我们通过「订单事实流 + 用户维表」构建了一条基础的实时数仓链路。
但在实际操作 Flink SQL Client 时,你可能已经痛感到了一个问题:
痛点:会话窗口一旦关闭,或者 Flink 集群重启,辛辛苦苦编写的
CREATE TABLE、CREATE VIEW等 DDL 语句瞬间“归零”。每次调试都需要从头再来,重复建表。
2026/2/25大约 12 分钟
在上一篇 《从零开始学Flink:实时数仓与维表时态Join实战》 中,我们通过「订单事实流 + 用户维表」构建了一条基础的实时数仓链路。
但在实际操作 Flink SQL Client 时,你可能已经痛感到了一个问题:
痛点:会话窗口一旦关闭,或者 Flink 集群重启,辛辛苦苦编写的
CREATE TABLE、CREATE VIEW等 DDL 语句瞬间“归零”。每次调试都需要从头再来,重复建表。
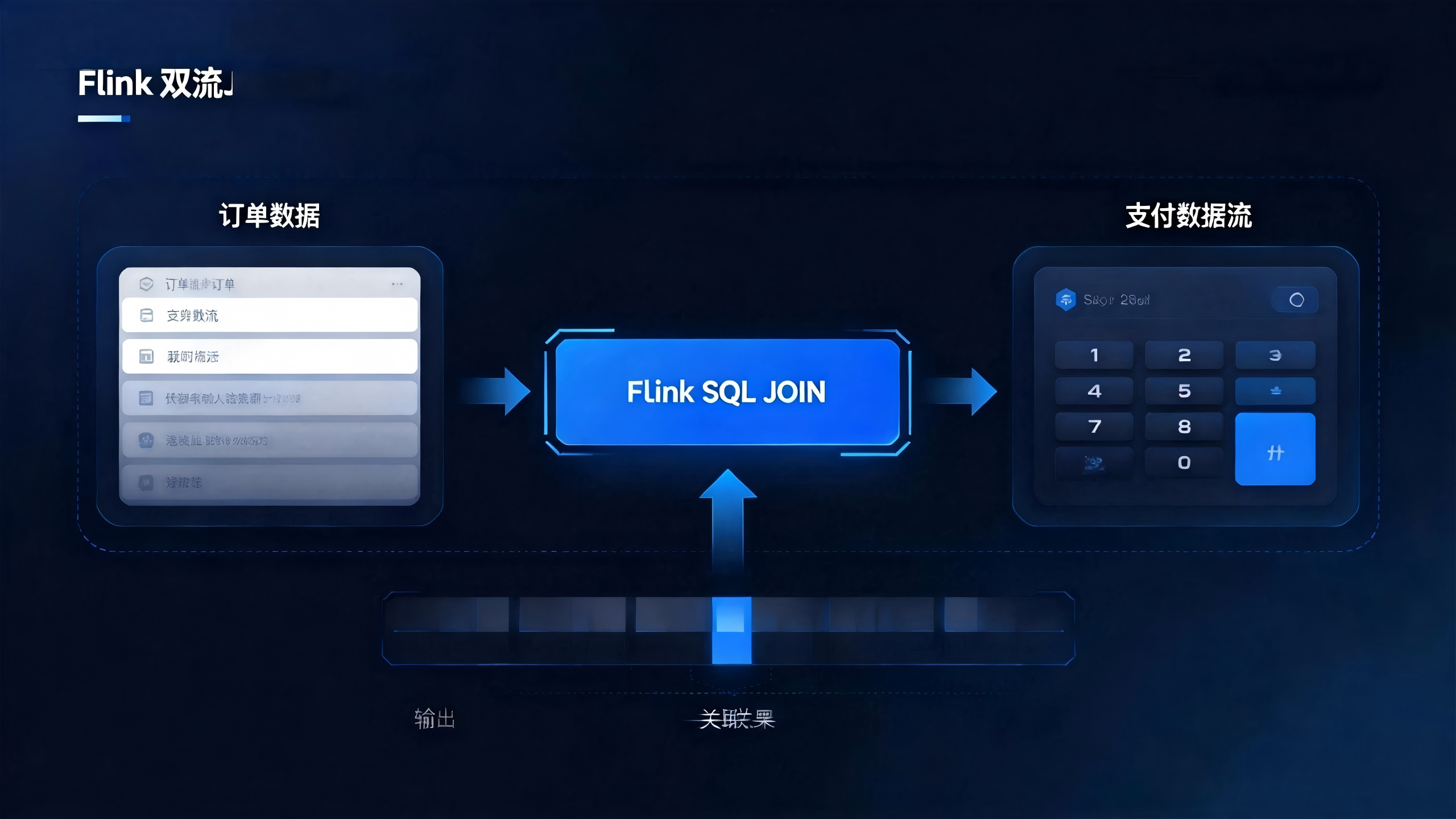
在前一篇 《Flink 双流 JOIN 实战详解》 中,我们用「订单流 + 支付流」搞懂了事实双流之间的时间关联。
但在真实的实时数仓项目里,光有事实流还不够,业务同学更关心的是:
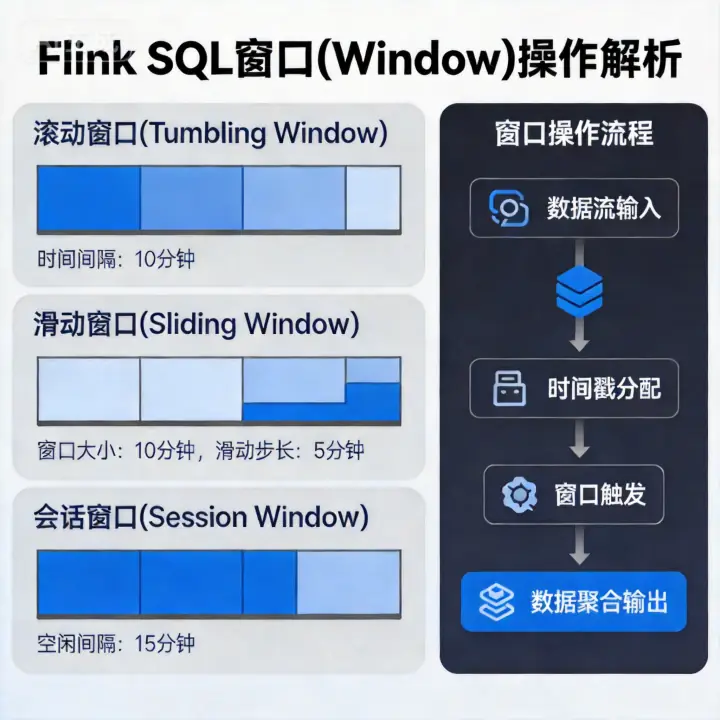
在前一篇 《Flink SQL 窗口(Window)操作详解》 中,我们已经打好了时间与窗口的基础。
但在真实业务里,单条流上的聚合往往只是第一步,更常见的需求是把多条业务流关联起来一起看,例如:
在上一篇 Flink SQL 极简入门 中,我们体验了 Flink SQL 的基础用法。但在流处理中,最核心、最迷人(也最让人头秃)的概念莫过于**“时间”和“窗口(Window)”**。
你可能经常听到这样的业务需求:
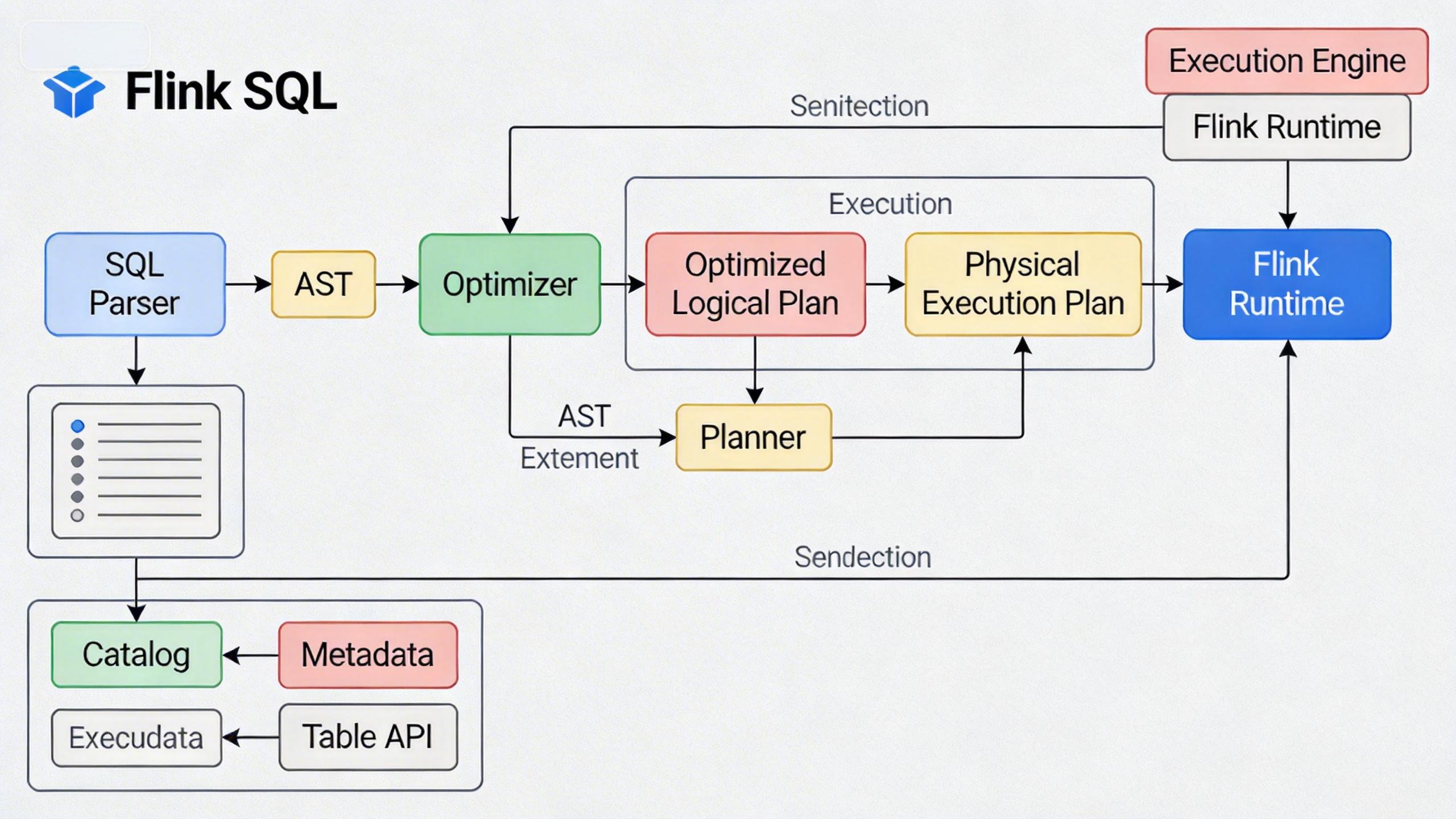
Flink SQL 是 Apache Flink 的核心模块之一,它让开发者可以使用标准的 SQL 语法来编写流处理和批处理作业。对于不想深究 Java/Scala 复杂 API 的“小白”来说,Flink SQL 是进入实时计算领域的最佳敲门砖。
本文将基于 Flink 1.20.1 版本,手把手教你在 WSL2 (Ubuntu) 环境下搭建环境,并运行你的第一个 Flink SQL 任务。